
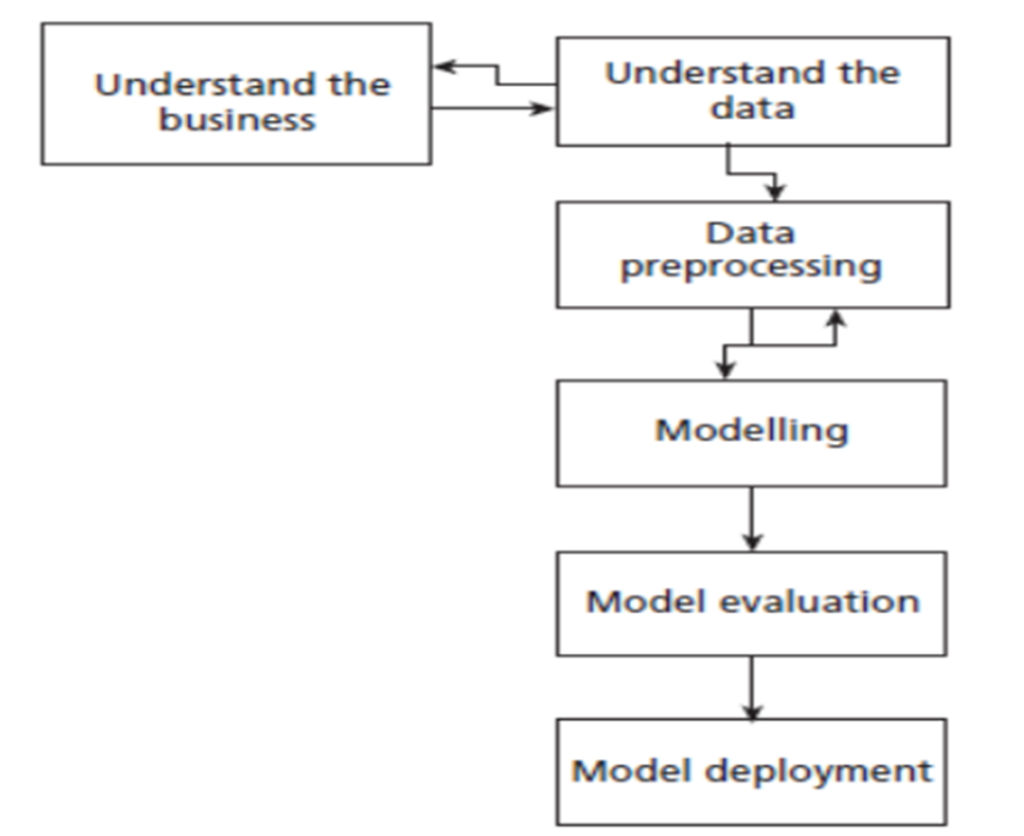
Machine learning follows a structured process to develop models that can make predictions or automate decision-making. Let’s explore each step as illustrated in block diagram in detail with an example where a bank wants to predict whether a customer will default on a loan or not.
1. Understand the Business
Before building a machine learning model, it is crucial to understand the business problem. This step involves discussions with stakeholders, defining objectives, and identifying the key performance indicators (KPIs).
✅ Example:
A bank faces financial losses due to loan defaults. The goal is to build a predictive model that can classify whether a new loan applicant is likely to default or not. By identifying high-risk customers, the bank can take precautionary measures such as offering smaller loans or requiring higher credit scores.
2. Understand the Data
Once the problem is defined, the next step is to explore and analyze the available data. This involves checking the dataset’s features, distributions, and relationships.
✅ Example:
The bank collects customer data with features such as:
- Age (Numerical)
- Income (Numerical)
- Loan Amount (Numerical)
- Credit Score (Numerical)
- Past Loan Repayment History (Categorical: Paid/Defaulted)
The dataset is analyzed to find patterns. For example, customers with low credit scores and high loan amounts might have a higher tendency to default.
3. Data Preprocessing
Raw data is often incomplete, inconsistent, or noisy. Data preprocessing ensures the data is clean and suitable for modeling.
✅ Example:
- Handling Missing Values: If some customers have missing credit scores, we fill them with the median credit score.
- Encoding Categorical Data: Converting categorical data into numerical form (e.g., “Paid” → 0, “Defaulted” → 1).
- Feature Scaling: Standardizing numerical data (e.g., normalizing income and loan amounts).
- Splitting Data: The dataset is divided into training data (80%) and testing data (20%) for model evaluation.
4. Modelling
In this step, we select a machine learning algorithm and train it using historical data. Common models for classification include Logistic Regression, Decision Trees, Random Forest, and Neural Networks.
✅ Example:
The bank decides to use Logistic Regression, a classification algorithm, to predict loan defaults. The model learns relationships between the input variables (credit score, loan amount, income, etc.) and the target variable (default or not).
5. Model Evaluation
After training the model, we evaluate its performance using different metrics. This ensures the model generalizes well to unseen data.
✅ Example:
The bank evaluates its logistic regression model using:
- Accuracy: Measures how many predictions were correct.
- Precision & Recall: Useful for imbalanced datasets where one class (default) is less frequent.
- Confusion Matrix: Helps understand the number of true positives, true negatives, false positives, and false negatives.
Suppose the model has an accuracy of 85%, meaning it correctly predicts loan defaults in 85 out of 100 cases. If the recall is low, the bank may retrain the model using additional data or a different algorithm.
6. Model Deployment
A well-performing model is deployed into production, where it is used to make real-world decisions.
✅ Example:
The bank integrates the model into its loan approval system. When a customer applies for a loan, the model analyzes their details and predicts whether they are likely to default (1) or not default (0).
- If the model predicts default (1), the bank may reject the loan or impose stricter conditions.
- If the model predicts not default (0), the bank can approve the loan.
The model is continuously monitored, and periodic retraining is performed to improve its accuracy over time.
Conclusion
The machine learning process is iterative. If a model performs poorly, we go back to data preprocessing, feature engineering, or model selection to improve it. In our loan default prediction example, machine learning helps the bank reduce financial risk, improve decision-making, and optimize loan approvals efficiently



