

What is Machine Learning?
Machine Learning (ML) is a branch of artificial intelligence (AI) that enables computers to learn from data and make decisions without being explicitly programmed. Instead of relying on predefined rules, ML algorithms analyze data patterns and improve their performance over time as they are exposed to more data. This capability makes machine learning a powerful tool for automating tasks, uncovering insights, and building intelligent systems.
Labelled and Unlabeled Data
In machine learning, the type of data used for training models plays a crucial role in determining the accuracy and effectiveness of the algorithm. Data can be classified into labeled and unlabeled data based on whether or not it has predefined target values (labels).
1. Labeled Data
Definition:
Labeled data is a dataset that contains both features (input variables) and labels (output categories or target values). Each data point has a corresponding answer or outcome that the machine learning model can use to learn. This type of data is primarily used in supervised learning.
Key Characteristics:
- Contains both input features and output labels.
- Used in classification and regression tasks.
- Requires manual labeling, which can be expensive and time-consuming.
Example 1: Iris Flower Dataset (Structured Data)
| Length of Petal | Width of Petal | Length of Sepal | Width of Sepal | Class (Label) |
|---|---|---|---|---|
| 5.5 | 4.2 | 1.4 | 0.2 | Setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | Versicolor |
| 7.3 | 2.9 | 6.3 | 1.8 | Virginica |
👉 Use Case: The model is trained to predict the type of iris flower (Setosa, Versicolor, or Virginica) based on its petal and sepal measurements.
Example 2: Email Spam Detection (Text Data)
| Email Content | Label |
|---|---|
| “Congratulations! You won $1000 cash!” | Spam |
| “Meeting scheduled for tomorrow at 10 AM.” | Not Spam |
| “Click this link to claim your free prize!” | Spam |
👉 Use Case: The model learns to classify emails as “Spam” or “Not Spam” using supervised learning.
Example 3: Image Classification (Image Data)
| Image | Label |
|---|---|
| 🐶 (Dog Image) | Dog |
| 🐱 (Cat Image) | Cat |
| 🏎️ (Car Image) | Car |
👉 Use Case: A deep learning model uses labeled images to classify objects as “Dog,” “Cat,” or “Car.”
Other Real-World Examples of Labeled Data:
- Medical Diagnosis: X-ray images labeled as “Pneumonia” or “Normal.”
- Speech Recognition: Audio clips labeled with their transcriptions.
- Sentiment Analysis: Social media posts labeled as “Positive,” “Negative,” or “Neutral.”
2. Unlabeled Data
Definition:
Unlabeled data contains only features (input variables) but no predefined output labels. The machine learning model must find patterns, relationships, or clusters on its own. This type of data is mainly used in unsupervised learning.
Key Characteristics:
- Only contains input features, no predefined labels.
- Used in clustering, anomaly detection, and dimensionality reduction tasks.
- Requires algorithms to detect hidden patterns without guidance.
Example 1: Customer Segmentation (Structured Data)
| Customer Age | Spending Score |
|---|---|
| 25 | 85 |
| 40 | 40 |
| 60 | 20 |
👉 Use Case: The model groups customers into segments (e.g., “High Spenders,” “Moderate Spenders,” “Low Spenders”) based on spending behavior.
Example 2: Topic Modeling in News Articles (Text Data)
| News Article Content |
|---|
| “Stocks surged in the market today as tech companies…” |
| “The new football season started with an intense match…” |
| “Scientists discovered a new exoplanet with Earth-like conditions…” |
👉 Use Case: The model identifies clusters of articles related to finance, sports, or science without predefined labels.
Example 3: Unlabeled Images for Object Detection (Image Data)
| Image |
|---|
| 🏠 (House Image) |
| 🌳 (Tree Image) |
| 🚗 (Car Image) |
👉 Use Case: A machine learning model detects and categorizes objects in images without prior labeling.
Other Real-World Examples of Unlabeled Data:
- Anomaly Detection: Identifying fraudulent transactions without predefined fraud labels.
- Self-Driving Cars: Processing road images without labeled traffic objects.
- Market Basket Analysis: Identifying frequently bought products without explicit customer categories.
Comparison Table: Labeled vs. Unlabeled Data
| Feature | Labeled Data | Unlabeled Data |
|---|---|---|
| Definition | Data with both features and labels | Data with only features, no labels |
| Example Dataset | Iris Flower Dataset (has class labels) | Customer Segmentation Data (no labels) |
| Learning Type | Supervised Learning | Unsupervised Learning |
| Usage | Classification, Regression | Clustering, Anomaly Detection |
| Example in Image Classification | Dog image labeled as “dog” | Image dataset without labels |
| Real-World Example | Spam vs. Not Spam emails | Grouping customers by behavior |
| Data Labeling Effort | Requires human annotation | No manual labeling needed |
| Algorithms Used | Decision Trees, Random Forest, Neural Networks | K-Means, Hierarchical Clustering, Autoencoders |
Note:
- Labeled Data is essential for supervised learning, where models learn from examples with predefined answers.
- Unlabeled Data is used in unsupervised learning, where models discover hidden patterns without labeled guidance.
- Semi-Supervised Learning combines both approaches to leverage the benefits of labeled data while utilizing large amounts of unlabeled data.
How Machine Learning Works – Example with House Price Prediction
Step 1: Collect Data
Machine learning starts by collecting data. Suppose we want to predict the price of houses based on their size and number of bedrooms. We gather the following data:
| Size (sq ft) | Bedrooms | Price ($) |
|---|---|---|
| 1400 | 3 | 300,000 |
| 1600 | 3 | 340,000 |
| 1700 | 4 | 360,000 |
| 1875 | 3 | 400,000 |
| 1100 | 2 | 200,000 |
Step 2: Choose a Model – Linear Regression
We choose a Linear Regression model because it assumes the relationship between house features (Size, Bedrooms) and Price is linear. The model can be expressed as an equation:
Price=w1×Size+w2×Bedrooms+b
Where:
- Price: Predicted price of the house.
- Size: Size of the house in square feet.
- Bedrooms: Number of bedrooms.
- w1, w2: Weights (coefficients) learned by the model.
- b: Bias (intercept).
Step 3: Train the Model
The training process involves feeding the collected data into the model. The model learns the values of w1, w2, and b so that it minimizes the difference between predicted prices and actual prices in the dataset.
Example (Assuming the model learns the following values after training):
- w1 = 200
- w2 = 10,000
- b = 50,000
Step 4: Make Predictions
After training, we can use the model to predict the price of a new house. Suppose we want to predict the price of a house with:
- Size = 1500 sq ft
- Bedrooms = 3
Using the learned values in the model’s equation:
Price=(200×1500)+(10,000×3)+50,000
Price=300,000+30,000+50,000=380,000
The predicted price is $380,000.
Step 5: Evaluate and Improve
We compare the predictions with actual prices (if available). If the predictions are not accurate, we can:
- Collect more data.
- Adjust the model.
- Use a different machine learning algorithm.
Real-time Examples of Machine Learning:
- Email Spam Filters: Machine learning algorithms analyze email content to automatically detect and filter spam messages.
- Recommendation Systems: Platforms like Netflix, YouTube, and Amazon suggest movies, videos, or products based on your viewing or purchasing history.
- Voice Assistants: Virtual assistants like Siri, Alexa, and Google Assistant use machine learning to understand and respond to voice commands.
- Fraud Detection: Banks and financial institutions use ML to detect unusual patterns and prevent fraudulent transactions.
- Self-Driving Cars: Autonomous vehicles use ML to interpret sensor data, recognize objects, and make driving decisions.
- Healthcare Diagnostics: ML models help doctors diagnose diseases from medical images like X-rays and MRI scans.
Types of Machine Learning
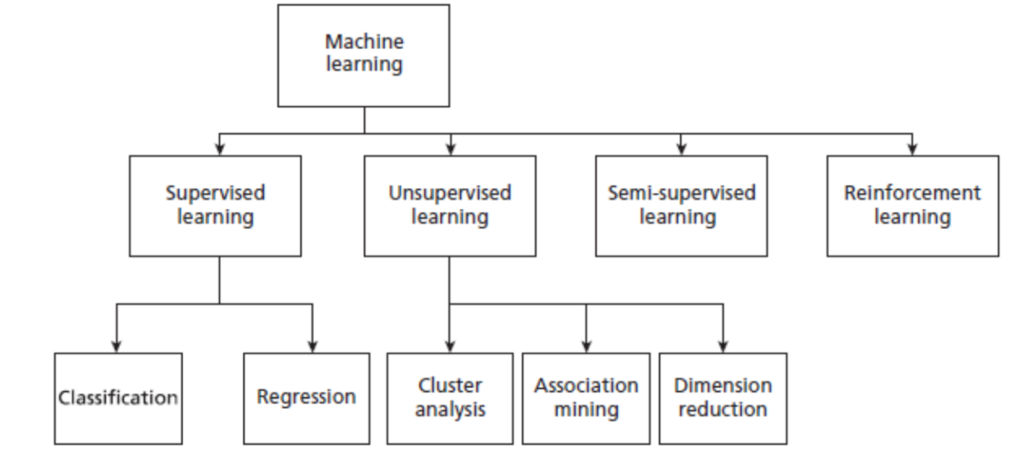
Machine Learning is broadly categorized into four main types:
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
Each type has distinct characteristics and applications. Let’s explore them in detail.
1. Supervised Learning
Definition:
Supervised learning is a type of machine learning where the model is trained using labeled data. The model learns the relationship between input features and corresponding output labels to make predictions.
Subcategories:
- Classification – The output variable is categorical (e.g., “spam” or “not spam”).
- Regression – The output variable is continuous (e.g., predicting house prices).
Examples:
- Classification:
- Email spam detection (Spam or Not Spam).
- Handwritten digit recognition (Digits 0-9).
- Regression:
- Predicting house prices based on square footage and location.
- Forecasting stock market trends.
Algorithms Used:
- Classification: Logistic Regression, Decision Trees, Random Forest, Support Vector Machine (SVM), Neural Networks.
- Regression: Linear Regression, Polynomial Regression, Support Vector Regression (SVR), Neural Networks.
2. Unsupervised Learning
Definition:
Unsupervised learning is a machine learning approach where the model is trained using unlabeled data. The system finds hidden patterns, relationships, or structures in the data without predefined categories.
Subcategories:
- Cluster Analysis (Clustering): Groups similar data points together.
- Association Mining: Identifies relationships between different items in a dataset.
- Dimension Reduction: Reduces the number of input variables while retaining important information.
Examples:
- Clustering:
- Customer segmentation in marketing (grouping customers based on purchase behavior).
- Image compression (grouping similar pixels).
- Association Mining:
- Market Basket Analysis (e.g., Amazon suggesting “People who bought this also bought…”).
- Identifying frequently purchased product combinations.
- Dimension Reduction:
- Principal Component Analysis (PCA) for data visualization.
- Feature selection in high-dimensional datasets like genetics research.
Algorithms Used:
- Clustering: K-Means, Hierarchical Clustering, DBSCAN.
- Association Mining: Apriori Algorithm, FP-Growth.
- Dimension Reduction: Principal Component Analysis (PCA), t-SNE.
3. Semi-Supervised Learning
Definition:
Semi-supervised learning is a hybrid approach that uses a small amount of labeled data along with a large amount of unlabeled data. It bridges the gap between supervised and unsupervised learning.
Examples:
- Medical Diagnosis: Training a model with a few labeled MRI scans and many unlabeled ones.
- Speech Recognition: Using a small set of transcribed speech data and a larger dataset of untranscribed speech.
- Fraud Detection: Identifying fraudulent transactions with limited labeled data.
Algorithms Used:
- Self-Training, Label Propagation, Semi-Supervised Support Vector Machines (S3VM).
4. Reinforcement Learning
Definition:
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties. The goal is to maximize the cumulative reward over time.
Examples:
- Game Playing:
- AlphaGo (Google’s AI beating human champions in Go).
- AI mastering video games (e.g., DeepMind’s AI playing Atari games).
- Robotics:
- Self-driving cars adjusting to road conditions.
- Industrial robots optimizing workflows.
- Finance:
- Automated trading algorithms adjusting strategies based on market trends.
Algorithms Used:
- Q-Learning, Deep Q Networks (DQN), Policy Gradient Methods, Actor-Critic Methods.
Comparison Table
| Learning Type | Labeled Data? | Main Goal | Example Applications | Algorithms Used |
|---|---|---|---|---|
| Supervised Learning | ✅ Yes | Learn from labeled data to make predictions | Spam detection, House price prediction | Decision Trees, Random Forest, Neural Networks |
| Unsupervised Learning | ❌ No | Discover patterns in data | Customer segmentation, Market Basket Analysis | K-Means, DBSCAN, PCA |
| Semi-Supervised Learning | ✅⚠️ Partially | Leverage both labeled and unlabeled data | Speech recognition, Fraud detection | Self-Training, Label Propagation |
| Reinforcement Learning | ❌ No | Learn by trial and error using rewards | Self-driving cars, Game AI | Q-Learning, Deep Q Networks (DQN) |
Note:
- Supervised Learning is best for predictive modeling tasks where labeled data is available.
- Unsupervised Learning is useful for finding hidden patterns in unlabeled datasets.
- Semi-Supervised Learning is ideal when labeled data is scarce and expensive to obtain.
- Reinforcement Learning is suited for decision-making tasks where an agent interacts with an environment.
List of Machine Learning Algorithms
Supervised Learning Algorithms
- Linear Regression:
- Description: Models the relationship between variables by fitting a linear equation to the data.
- Uses: Predicting house prices, sales forecasting.
- Logistic Regression:
- Description: Used for binary classification; estimates probabilities using a logistic function.
- Uses: Disease diagnosis, credit scoring.
- Decision Trees:
- Description: Splits data into branches based on feature values to make decisions.
- Uses: Customer segmentation, risk assessment.
- Support Vector Machines (SVM):
- Description: Finds the optimal hyperplane that separates classes in high-dimensional space.
- Uses: Image recognition, text classification.
- K-Nearest Neighbors (KNN):
- Description: Classifies data based on the majority class among its nearest neighbors.
- Uses: Pattern recognition, recommendation systems.
- Naive Bayes:
- Description: Based on Bayes’ theorem; assumes feature independence.
- Uses: Spam filtering, sentiment analysis.
- Random Forest:
- Description: Ensemble of decision trees; reduces overfitting.
- Uses: Medical diagnosis, financial modeling.
- Gradient Boosting Machines (GBM):
- Description: Builds models sequentially, correcting previous errors.
- Uses: Ranking, credit risk assessment.
Unsupervised Learning Algorithms
- K-Means Clustering:
- Description: Partitions data into k clusters based on similarity.
- Uses: Customer segmentation, pattern recognition.
- Hierarchical Clustering:
- Description: Builds a hierarchy of clusters using a bottom-up approach.
- Uses: Gene analysis, social network analysis.
- Principal Component Analysis (PCA):
- Description: Reduces dimensionality by transforming data into principal components.
- Uses: Data visualization, noise reduction.
- Apriori Algorithm:
- Description: Identifies frequent itemsets in transactional data.
- Uses: Market basket analysis, association rule mining.
- DBSCAN (Density-Based Spatial Clustering):
- Description: Clusters data points based on density.
- Uses: Anomaly detection, geospatial analysis.
Reinforcement Learning Algorithms
- Q-Learning:
- Description: Model-free algorithm; learns the value of actions to maximize rewards.
- Uses: Game AI, robotics.
- Deep Q Network (DQN):
- Description: Combines Q-learning with deep neural networks.
- Uses: Complex game environments, autonomous driving.
- Policy Gradient Methods:
- Description: Optimize policies directly through gradient ascent.
- Uses: Robotics, real-time decision-making.
Deep Learning Algorithms
Deep Learning algorithms are actually a subset of machine learning, but they are often treated as a distinct category because they involve neural networks with many layers (hence the term deep). They are particularly powerful for handling large volumes of data and complex tasks like image recognition, natural language processing, and autonomous driving. Some Common algorithms
- Artificial Neural Networks (ANN):
- Description: A network of interconnected nodes (neurons) that can model complex patterns in data.
- Uses: Image recognition, speech recognition.
- Convolutional Neural Networks (CNN):
- Description: Specialized for processing grid-like data, particularly images.
- Uses: Image classification, object detection.
- Recurrent Neural Networks (RNN):
- Description: Designed for sequential data; maintains memory of previous inputs.
- Uses: Time series prediction, natural language processing.
- Long Short-Term Memory Networks (LSTM):
- Description: A type of RNN that can learn long-term dependencies.
- Uses: Speech recognition, stock price prediction.
- Generative Adversarial Networks (GANs):
- Description: Consists of two networks (generator and discriminator) competing to generate realistic data.
- Uses: Image synthesis, deepfakes.
- Autoencoders:
- Description: Neural networks designed to encode data into a compressed representation and then decode it back.
- Uses: Anomaly detection, image denoising.
| Algorithm Type | Algorithm Name | Description | Use Cases |
|---|
| Supervised Learning | Linear Regression | Models the relationship between variables by fitting a linear equation to the data. | Predicting house prices, sales forecasting, predicting student performance. |
| Logistic Regression | Used for binary classification; estimates probabilities using a logistic function. | Disease diagnosis (diabetes prediction), customer churn prediction, spam email detection. |
| Decision Trees | Splits data into branches based on feature values to make decisions. | Loan approval systems, medical diagnosis, customer segmentation. |
| Support Vector Machines (SVM) | Finds the optimal hyperplane that separates classes in high-dimensional space. | Face detection, text classification, handwriting recognition. |
| K-Nearest Neighbors (KNN) | Classifies data based on the majority class among its nearest neighbors. | Recommender systems (movie and product recommendations), credit rating, anomaly detection. |
| Naive Bayes | Based on Bayes’ theorem; assumes feature independence. | Spam filtering, sentiment analysis, document classification. |
| Random Forest | Ensemble of decision trees; reduces overfitting and improves accuracy. | Fraud detection, medical diagnosis, predicting customer behavior. |
| Gradient Boosting Machines (GBM) | Builds models sequentially, correcting previous errors to improve accuracy. | Credit scoring, ranking search engine results, predicting stock market trends. |
| Unsupervised Learning | K-Means Clustering | Partitions data into k clusters based on similarity. | Customer segmentation, image compression, market segmentation. |
| Hierarchical Clustering | Builds a hierarchy of clusters using a bottom-up approach. | Social network analysis, gene expression analysis, document categorization. |
| Principal Component Analysis (PCA) | Reduces dimensionality by transforming data into principal components. | Face recognition, data visualization, noise reduction in datasets. |
| Apriori Algorithm | Identifies frequent itemsets in transactional data and finds association rules. | Market basket analysis (e.g., Amazon’s “Frequently Bought Together” feature), recommendation systems, medical diagnosis. |
| DBSCAN (Density-Based Spatial Clustering) | Clusters data points based on density without requiring the number of clusters in advance. | Anomaly detection (fraud detection in banking), geospatial data clustering, network intrusion detection. |
| Reinforcement Learning | Q-Learning | Model-free algorithm; learns the value of actions to maximize rewards. | Game playing (Chess, Go, Atari games), autonomous robotics, warehouse optimization. |
| Deep Q Network (DQN) | Combines Q-learning with deep neural networks to handle high-dimensional state spaces. | Self-driving cars, AI-based game agents, automated financial trading. |
| Policy Gradient Methods | Optimize policies directly through gradient ascent for decision-making. | Robotics (robot arm movements), healthcare treatment planning, self-learning chatbots. |
| Deep Learning | Artificial Neural Networks (ANN) | A network of interconnected nodes (neurons) that model complex patterns in data. | Fraud detection, speech recognition, stock market forecasting. |
| Convolutional Neural Networks (CNN) | Specialized for processing grid-like data, particularly images. | Image classification (facial recognition, medical imaging), autonomous vehicles (object detection), satellite image analysis. |
| Recurrent Neural Networks (RNN) | Designed for sequential data; maintains memory of previous inputs. | Machine translation (Google Translate), time-series forecasting, handwriting recognition. |
| Long Short-Term Memory Networks (LSTM) | A type of RNN that can learn long-term dependencies in sequential data. | Speech recognition (Alexa, Siri), chatbot development, predictive maintenance in industrial settings. |
| Generative Adversarial Networks (GANs) | Consists of two networks (generator and discriminator) competing to generate realistic data. | Image generation (deepfake technology), art creation, drug discovery. |
| Autoencoders | Neural networks designed to encode data into a compressed representation and then decode it back. | Anomaly detection (detecting fraud in transactions), image noise reduction, data compression. |
Conclusion
Machine learning algorithms have revolutionized industries by enabling systems to learn from data and make intelligent decisions. Understanding different types and their applications is crucial for leveraging ML to solve real-world problems efficiently. As technology advances, machine learning will continue to be a driving force behind innovation and automation.









